{kind=link}
Evaluation of Expressions
- Mini-topic: Materialization (Page 724)
- Micro-topic: Figure 15.11 Pictorial representation of an expression. (Page 724)
- Mini-topic: Pipelining (Page 725)
- Micro-topic: Implementation of Pipelining (Page 726)
- Micro-topic: Evaluation Algorithms for Pipelining (Page 728)
- Micro-topic: Figure 15.12 Query plan with pipelining. (Page 729)
- Micro-topic: Figure 15.13 Double-pipelined join algorithm. (Page 730)
- Mini-topic: Pipelines for Continuous-Stream Data (Page 731)
Mini-topic: Materialization (Page 724)
Concept:
- Evaluate each operation’s result separately and store it in a temporary relation.
- These temporary relations are then used as input for the next level of operations.
- The process continues until the final operation (at the root of the expression tree) is evaluated.
Visual Representation: Think of an operator tree, like in Figure 15.11.
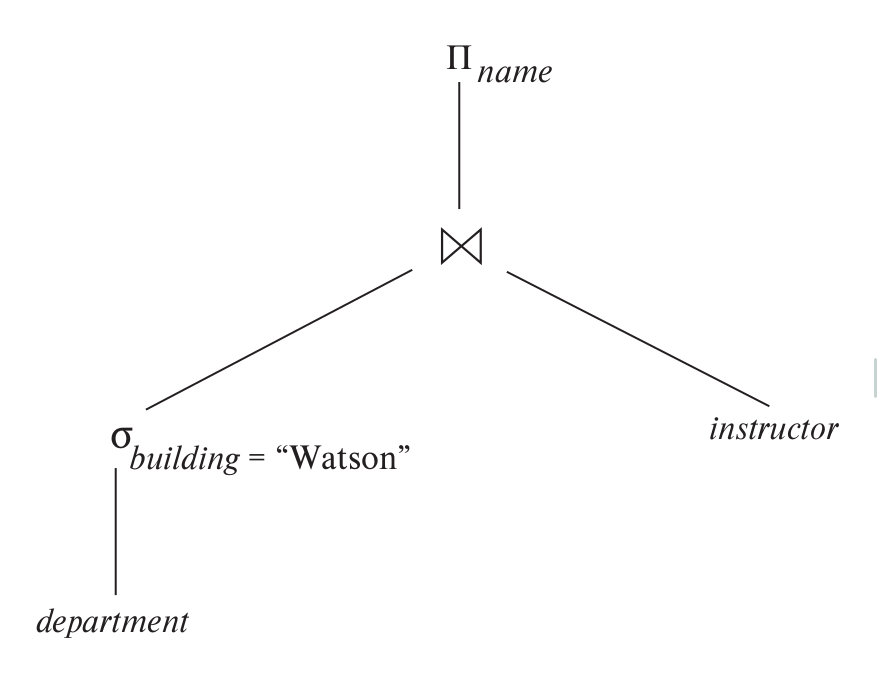
Process:
- Start at the lowest-level operations (leaves of the tree, accessing base relations).
- Execute these operations (e.g., selections, projections) using appropriate algorithms (from previous sections).
- Materialize the results: Write the output of each operation to a temporary relation on disk.
- Move up to the next level. Use the temporary relations (or base relations) as input.
- Repeat until the root operation is evaluated, producing the final result.
Cost:
-
The total cost is the sum of:
- Costs of individual operations (using algorithms from previous sections).
- Cost of writing intermediate results to disk.
-
Writing to disk involves:
-
Block transfers: If is the number of tuples in the result and is the blocking factor (tuples per block), then the number of blocks, , is approximately:
-
Disk seeks (can be reduced with larger buffers or double buffering).
-
Advantages:
- Simple to implement.
- Easier to understand the flow of execution.
Disadvantages:
- High I/O cost due to writing and reading temporary relations. This is the main drawback.
Mini-topic: Pipelining (Page 725)
Concept:
- Evaluate multiple operations simultaneously in a “pipeline.”
- Results of one operation are passed directly to the next operation, without storing them in temporary relations.
- It is also called on-the-fly.
Process:
- Combine several relational operations into a pipeline.
- As one operation generates tuples, it immediately passes them to the next operation in the pipeline.
- No intermediate relations are written to disk (in the ideal case).
Advantages:
- Reduced I/O cost: Eliminates the need to write and read temporary relations. This is a major performance improvement.
- Faster initial results: If the final operation is part of the pipeline, the user can start seeing results much sooner. This is crucial for interactive queries.
Disadvantages:
- More complex to implement, requiring careful coordination between operations.
- Not all operations can be pipelined effectively (e.g., some joins, sorting).
Micro-topic: Implementation of Pipelining (Page 726)
There are 2 methods for implementing the Pipelining. 3. **Demand-driven pipeline** 4. **Producer-driven pipeline**-
Demand-Driven Pipelining (Lazy Evaluation):
- The system requests tuples from the operation at the top of the pipeline.
- Each operation, when it receives a request, computes the next tuple(s) it should return.
- To do this, it may need to request tuples from its input operations (which are part of the pipeline).
- This is like “pulling” data up the pipeline.
- Implemented using an iterator model:
open(): Initializes the operation’s state.next(): Returns the next output tuple. The operation internally callsnext()on its inputs as needed.close(): Cleans up resources.- The iterator maintains state between calls to
next()(e.g., current position in a file scan).
-
Producer-Driven Pipelining (Eager Evaluation):
-
Operations actively generate tuples and “push” them to the next operation in the pipeline.
-
Each operation is typically implemented as a separate process or thread.
-
Buffers are used between operations to hold tuples in transit.
-
An operation:
- Continually generates output tuples until its output buffer is full.
- Waits if its output buffer is full (and its parent hasn’t consumed tuples) or if its input buffer is empty (and it needs more input).
- Removes tuples from the input buffer as it uses them.
-
Well-suited for parallel processing.
-
Demand-Driven vs. Producer-Driven:
- Demand-driven is generally easier to implement.
- Producer-driven can be more efficient in parallel systems and may have lower overhead on modern CPUs.
Micro-topic: Evaluation Algorithms for Pipelining (Page 728)
Pipeline edges Blocking edges Pipeline stage *Blocking operations
-
Not all relational algebra operations are equally suited for pipelining.
-
Pipeline edges:
- The edges between operators that combined in pipelining.
-
Blocking edges/Materialized edges:
- Edges where full output must be generated by source operator, before next operator can start.
-
Pipeline stage:
- A set of operators that are connected with pipelined edges.
- A query can be broken into subtrees such that each subtree, known as pipeline stage, has only pipelined edges.
-
Blocking Operations: Some operations, like sorting, are inherently blocking. They cannot produce any output until they have seen all their input. This limits the extent of pipelining.
- Example Sort-merge: Even sort-merge has stages. Run generation can be pipelined with its input. The merge phase can be pipelined with its output. But the merge phase cannot start until run generation is complete.
-
Join Algorithms:
- Indexed nested-loop join: Can be pipelined with its outer relation (but is blocking on its inner, indexed relation).
- Hash join: Is a blocking operation on the both inputs. The build must finish before the probe can occur. It is not suitable for pipelining the input.
-
Double Pipelined Join is also a technique that can be considered.
-
Pipelines for Continuous-Stream Data: * Pipelining is very important when dealing with continuous streams of data (e.g., sensor readings). * Queries over streams are often continuous queries that need to produce results as new data arrives. * Producer-driven pipelines are particularly well-suited for this. * Windowing and aggregation are common operations on streams. Results are output when the system knows no more tuples will arrive for a particular window.