{kind=link}
Hash Join
- Micro-topic: Basics (Page 712)
- Micro-topic: Figure 15.9 Hash partitioning of relations. (Page 713)
- Micro-topic: Figure 15.10 Hash join. (Page 714)
- Micro-topic: Recursive Partitioning (Page 714)
- Micro-topic: Handling of Overflows (Page 715)
- Micro-topic: Cost of Hash Join (Page 715)
Basics
Hash join is an efficient algorithm to implement natural joins and equi-joins. It leverages a hash function to partition tuples of both relations, improving performance.
Core Idea:
- Partition tuples of each relation into sets that have the same hash value on the join attributes.
- If an r tuple and an s tuple satisfy the join condition, they have the same value for the join attributes.
- Thus if that value of join attributes, is hashed to some value i, then r tuple must be in , and s tuple must be in .
- Therefore, r tuples in need to be compared only with s tuples in .
Assumptions:
- h: A hash function mapping
JoinAttrsvalues to {0, 1, …, }, whereJoinAttrsare the common attributes of r and s. - : Partitions of r tuples, initially empty. Each tuple is put in partition , where i = h(
[JoinAttrs]). - : Partitions of s tuples, initially empty. Each tuple is put in partition , where i = h(
[JoinAttrs]).
Hash Function Properties:
The hash function h should possess properties of randomness and uniformity.
Figure 15.9: Hash Partitioning of Relations.
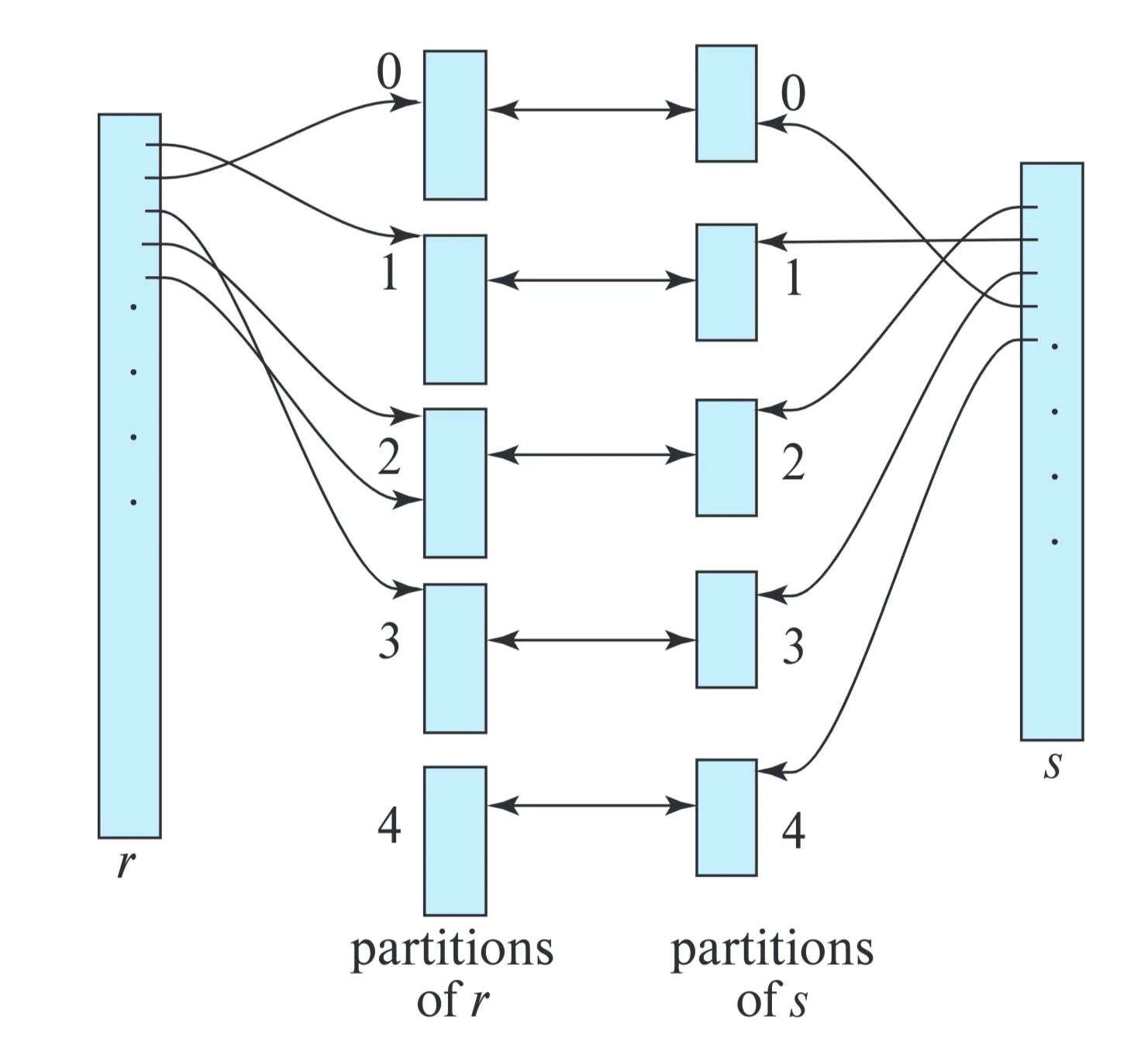
Database System Concepts 7, p.713
Illustrates visually how relations r and s are partitioned using the hash function h. Each partition is shown as a bucket.
Figure 15.10: Hash Join.
Provides the complete pseudocode of the hash-join algorithm for computing the natural join of relations r and s.
Algorithm
/* Partition s */
for each tuple ts in s do begin
i := h(ts[JoinAttrs]);
Hsi := Hsi ∪ {ts};
end
/* Partition r */
for each tuple tr in r do begin
i := h(tr[JoinAttrs]);
Hri := Hri ∪ {tr};
end
/* Perform join on each partition */
for i := 0 to nh do begin
read Hsi and build an in-memory hash index on it;
for each tuple tr in Hri do begin
probe the hash index on Hsi to locate all tuples ts
such that ts[JoinAttrs] = tr[JoinAttrs];
for each matching tuple ts in Hsi do begin
add tr ⋈ ts to the result;
end
end
end
Important Notes:
- The relations are partitioned based on hash value of join attributes.
- After partitioning, a separate indexed nested-loop join is performed on each of the partition pairs i, for i=0,…,.
- Build input: Relation s.
- Probe input: Relation r.
- The hash index on is built in memory.
- denotes concatenation of attributes of and , followed by removal of repeated attributes.
Recursive Partitioning
Scenario: When (number of partitions) is large, exceeding available memory blocks, one pass partitioning is not possible.
Solution: Recursive Partitioning
- Multiple Passes: The partitioning process is performed in multiple passes.
- Buffer Limit: In one pass, input can be split into at most as many partitions as there are output buffer blocks.
- Iterative Refinement: Each bucket from one pass is read and partitioned again in the next pass, creating smaller partitions.
- Different hash function is used in each pass.
- Termination: Splitting is repeated until each partition of the build input fits in memory.
Handling of Overflows
Hash-Table Overflow: Occurs in partition i of build relation s if the hash index on is larger than main memory. * Caused by many tuples with the same join attribute values, or a non-uniform/non-random hash function. * Results in skewed partitioning.
Mitigation Techniques:
-
Increase (Fudge Factor):
- Increase the number of partitions so expected partition size is less than memory size.
- Fudge factor: Increase by about 20% to be conservative.
-
Overflow Resolution:
- Performed during build phase if overflow is detected.
- If is too large, further partition it (and ) using a different hash function.
-
Overflow Avoidance:
- Partition s into many small partitions initially.
- Combine partitions so each combined partition fits in memory.
- Partition r in the same way (sizes of don’t matter).
Failure Condition: If many tuples in s have the same value for join attributes, resolution/avoidance may fail. Use other join methods (e.g., block nested-loop join) on those partitions.
Cost of Hash Join
Assumptions
- No hash table overflow.
Case: No recursive partitioning required.
-
Partitioning:
- Reads and writes both relations completely: 2( + ) block transfers.
- Slight overhead for partially filled blocks: at most 2 extra blocks for each relation.
-
Build and Probe:
- Reads each partition once: + block transfers.
-
Total Block Transfers: Approximately 3( + ) + 4.
-
Mini-topic: Disk seeks:
- Partitioning requires: 2(\lceil$$b_r/b_b$$\rceil+\lceil$$b_s/b_b$$\rceil)
- Build and probe require: 2 seeks.
- total seeks: 2(\lceil$$b_r/b_b$$\rceil+\lceil$$b_s/b_b$$\rceil)+2
Where denotes the number of blocks allocated for input buffer, and each output partition.
-
The 4 can be ignored as it will be very small.
Case: Recursive Partitioning required
-
Each pass reduces the partition size by an expected factor of \lfloor$$M/b_b$$\rfloor-1.
-
Passes repeat untill each partition is of size at most M blocks.
-
Number of Passes: \lceil$$log_{\lfloor M/b_b \rfloor-1}(/M).
-
Block Transfers: 2( + )\lceil$$log_{\lfloor M/b_b \rfloor-1}(/M) + +
-
Mini-topic: Disk seeks:
- 2(\lceil$$b_r/b_b$$\rceil+\lceil$$b_s/b_b$$\rceil)\lceil$$log_{\lfloor M/b_b \rfloor-1}(/M)