{kind=link}
Overview
- Goal: To generalize the centralized timestamping schemes (from Chapter 15) for a distributed environment. This involves ensuring a consistent ordering of transactions across multiple sites.
- Core Idea: Each transaction is assigned a unique timestamp. This timestamp is used to determine the serialization order. If transaction has timestamp , and transaction has timestamp , then if , the system must ensure the schedule is equivalent to a serial schedule where executed before .
Generating Unique Timestamps
The primary challenge in a distributed system is generating globally unique timestamps. Two main approaches exist:
1. Centralized Scheme
- A single site () is designated as the timestamp generator.
- This site can use either:
- A logical counter: Incremented after each timestamp is assigned.
- Its local clock: Assumes reasonably synchronized clocks across the system.
- Drawbacks:
- Becomes a single point of failure.
- May become performance bottleneck.
2. Distributed Scheme
-
Each site generates a local unique timestamp.
- Uses a logical counter or its local clock.
-
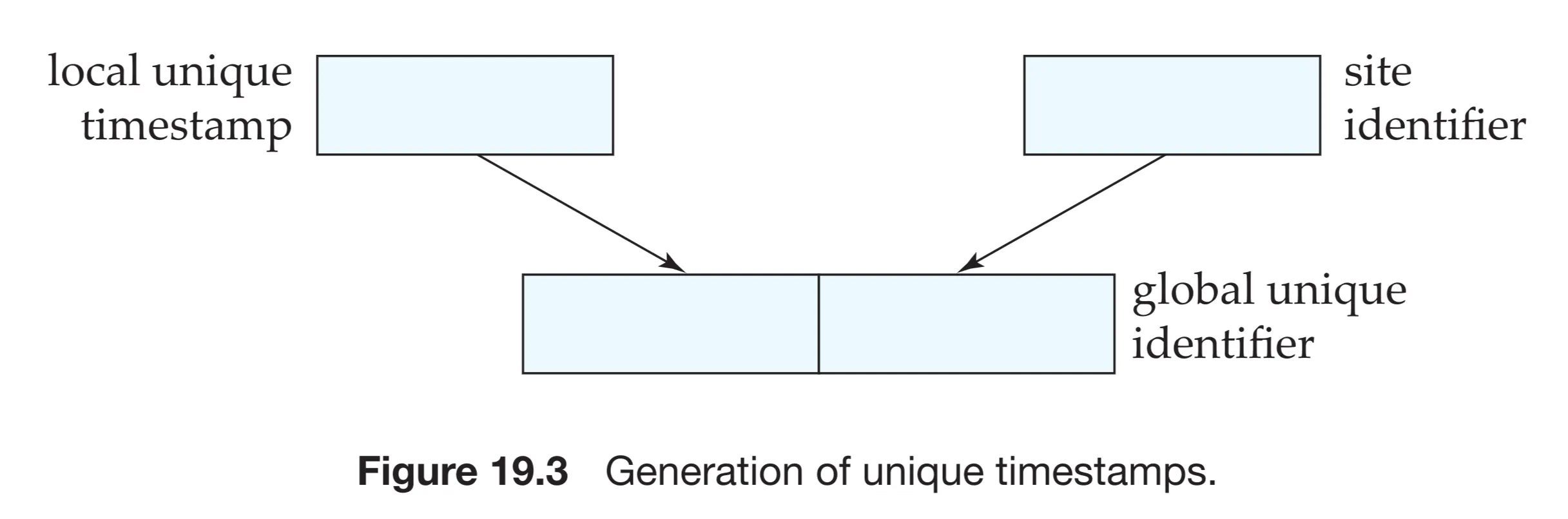
A global unique timestamp is created by concatenating the local timestamp with the site identifier.
-
Crucial: Site identifier is placed in the least significant position.
<Local Timestamp, Site Identifier>- Why least significant? To prevent a site with a faster clock (or rapidly incrementing counter) from always generating timestamps that appear “later” than those from other sites. This ensures fairness.
Example Visualization
- Why least significant? To prevent a site with a faster clock (or rapidly incrementing counter) from always generating timestamps that appear “later” than those from other sites. This ensures fairness.
Example Visualization
19. Distributed Databases, p.18
Maintaining Timestamp Fairness
-
Problem: A site () might generate local timestamps much faster than other sites. This could lead to all of ‘s transactions appearing to happen “later” than transactions at other sites, even if they occurred concurrently.
-
Solution: Logical Clocks
- Each site maintains a logical clock, .
- is (conceptually) a counter, incremented whenever a new local timestamp is generated.
- Synchronization Rule:
- When a transaction with timestamp visits site , and , then advances its logical clock:
- In essence: If sees a timestamp from another site that is “ahead” of its own clock, it catches up.
-
If System Clocks are Used:
- Similar synchronization rule.
- Prevents any single clock from getting too far ahead or behind. This requires mechanisms for clock synchronization, which is beyond the scope of basic timestamping.
Using Timestamps for Concurrency Control
Once unique timestamps are generated, the standard timestamp-based concurrency control protocols (from Chapter 15) can be applied with minimal modifications. Examples:
- Timestamp Ordering Protocol: The basic rules for read and write operations, comparing transaction timestamps with read-TS and write-TS of data items, are applied locally at each site. The global uniqueness of timestamps ensures consistency across the distributed system.
- Validation Protocol: Similar to the centralized version, but validation is done based on globally unique timestamps.
Key Advantages of Timestamping
- No Waiting: Transactions generally do not wait for locks. This can reduce delays.
- Deadlock-Free: Basic timestamp ordering protocols are inherently deadlock-free.
- Simple Implementation (Conceptually): Once timestamp generation is handled, the core protocols are similar to their centralized counterparts.
Potential Disadvantages
- Starvation: Transactions with later timestamps might repeatedly get aborted and restarted due to conflicts with earlier-timestamped transactions.
- Overhead: Maintaining timestamps (read-TS, write-TS) for each data item can add storage and processing overhead.
- Strict Timestamp Ordering Limitations: Strict ordering may sometimes lead to unnecessary aborts of transactions that could serialize, but the order doesn’t match timestamp order.